This documentation describes a release under development. Documentation for the latest release, 3.6.2, can be found here.
Amazon Redshift¶
Overview¶
Amazon Redshift can either be used as a data source or a data destination in Mitto.

Source plugin example: Query
Destination plugin examples: CSV, Salesforce, SQL
Amazon Redshift as a data destination¶
Mitto automatically creates the Amazon Redshift database schema if it doesn’t exist
Mitto automatically creates the Amazon Redshift database tables if they don’t exist
Mitto automatically determines data types for Amazon Redshift columns
Mitto automatically adds new columns to Amazon Redshift tables based on new fields in source systems
Mitto automatically adjusts Amazon Redshift tables based on changes in source data
Amazon Redshift specific setup¶
Below is the database url structure for connecting to a Amazon Redshift database:
redshift+psycopg2://<username>:<password>@<hostname>:5439/<database>
Here’s an example of using an Amazon Redshift database as a destination in a CSV job:
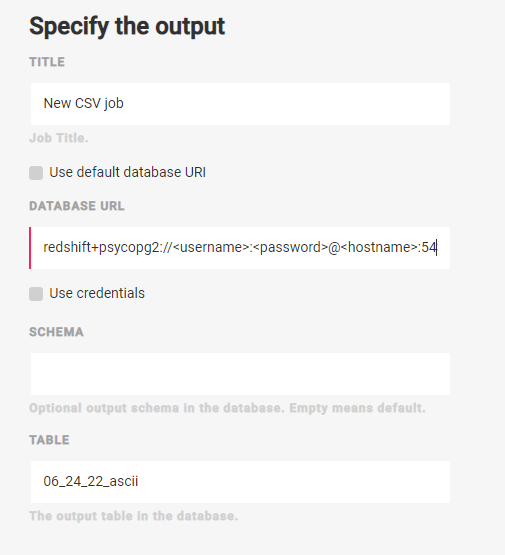
Note
When outputting to an Amazon Redshift database, leaving the “Schema” blank will create a table in the public schema.
Additional Redshift Required Key Values¶
Click DONE after complete the Specify the output screen. You will be taken to the job page. You now need to edit the job to add some additional key values that are unique to Redshift. Here is an example output with the required key values:
"output": {
"dbo": "redshift+psycopg2://{username}:{password}@{host}:5439/{database}",
"s3_access_key": "{access_key}",
"s3_secret_key": "{secret_key}",
"bucket": "{bucket}",
"schema": "{schema}",
"tablename": "{tablename}",
"use": "call:mitto.iov2.db#todb"
},
Replace {values} with your specific values without { }.
AWS IAM and S3 setup¶
Mitto uses COPY when using Amazon Redshift as a data destination. COPY requires additional AWS IAM and S3 credentials:
S3 access key
S3 secret key
S3 bucket
Mitto requires an AWS IAM user with Programmatic access for the access key and secret key.
Here is an example S3 policy that can be attached to the AWS IAM user:
{
"Version": "2012-10-17",
"Statement": [
{
"Action": [
"s3:*"
],
"Effect": "Allow",
"Resource": [
"arn:aws:s3:::bucket.name.zuar.com",
"arn:aws:s3:::bucket.name.zuar.com/*"
]
}
]
}
Replace bucket.name.zuar.com with the name of the S3 bucket Mitto will use for data transfer.
SQL¶
Mitto can send SQL statements to an Amazon Redshift database. Use Amazon Redshift syntax in these Mitto SQL jobs.