This documentation describes a release under development. Documentation for the latest release, 3.6.2, can be found here.
Store¶
Mitto has the ability to store source system data as JSON on the file system of the Mitto server.
The data is stored in a RocksDB key-value store.
Benefits of a Mitto Store¶
Seeing the “raw” data from the source system converted to JSON (even if the source system’s data was not in JSON originally)
Querying the source system ONCE per endpoint and allowing Mitto to query the JSON store for nested lists, rather than re-querying the source system again
Configuring a Mitto Job to use a Store¶
Mitto input/output (IO) jobs can be optionally configured to store raw source data as JSON.
A normal Mitto IO job’s JSON config has at least 3 key/value pairs: input,
output, and steps. You might also see an optional sdl key/value pair.
A Mitto IO job that uses a store has an additional store key/value pair.
Example Mitto JSON Job with Store¶
Example source JSON file:
[
{
"id": "1",
"type": "donut",
"name": "Cake",
"ppu": 0.55,
"batters":
{
"batter":
[
{ "id": "1001", "type": "Regular" },
{ "id": "1002", "type": "Chocolate" },
{ "id": "1003", "type": "Blueberry" },
{ "id": "1004", "type": "Devil's Food" }
]
},
"topping":
[
{ "id": "5001", "type": "None" },
{ "id": "5002", "type": "Glazed" },
{ "id": "5005", "type": "Sugar" },
{ "id": "5007", "type": "Powdered Sugar" },
{ "id": "5006", "type": "Chocolate with Sprinkles" },
{ "id": "5003", "type": "Chocolate" },
{ "id": "5004", "type": "Maple" }
]
},
{
"id": "2",
"type": "donut",
"name": "Raised",
"ppu": 0.55,
"batters":
{
"batter":
[
{ "id": "1001", "type": "Regular" }
]
},
"topping":
[
{ "id": "5001", "type": "None" },
{ "id": "5002", "type": "Glazed" },
{ "id": "5005", "type": "Sugar" },
{ "id": "5003", "type": "Chocolate" },
{ "id": "5004", "type": "Maple" }
]
},
{
"id": "3",
"type": "donut",
"name": "Old Fashioned",
"ppu": 0.55,
"batters":
{
"batter":
[
{ "id": "1001", "type": "Regular" },
{ "id": "1002", "type": "Chocolate" }
]
},
"topping":
[
{ "id": "5001", "type": "None" },
{ "id": "5002", "type": "Glazed" },
{ "id": "5003", "type": "Chocolate" },
{ "id": "5004", "type": "Maple" }
]
}
]
A Mitto job is created using this JSON file with a generic IO JSON job.
Job Title: [JSON] Donuts
Job Name: plugin_generic_job___json_donuts (The job name corresponds to the name of the store.)

Here’s the job config of the newly created job:
{
input: {
use: flatfile.iov2#JsonInput
source: /opt/mitto_data/data/example_donuts.json
}
output: {
tablename: donuts
use: call:mitto.iov2.db#todb
schema: demo
dbo: postgresql://db/analytics
}
steps: [
{
use: mitto.iov2.steps#Input
transforms: [
{
use: mitto.iov2.transform#ExtraColumnsTransform
}
{
use: mitto.iov2.transform#ColumnsTransform
}
]
}
{
use: mitto.iov2.steps#CreateTable
}
{
use: mitto.iov2.steps#Output
transforms: [
{
use: mitto.iov2.transform#FlattenTransform
}
]
}
{
use: mitto.iov2.steps#CollectMeta
}
]
}
When this job is run, the data from the JSON file is flattened into a database
table. In this case a table named donuts is created in Mitto’s internal
PostgreSQL database in the demo schema.
The job can be edited and configured to use a store:
{
"input": {
...
},
"output": {
...
},
"sdl": {
...
}
"steps": [
...
],
"store": {
"key": [
"$.id"
]
}
}
Note the addition of the store key/value pair. The store requires the
source data has at least a primary key. In this case the primary key is
id. The dollar sign in front of id us JSON Path Syntax.
To understand how to use JSONPath to pick specific sections of data out of a JSON object you can visit: https://goessner.net/articles/JsonPath/
To interactively learn how to use JSONPath syntax you can visit: https://jsonpath.com/
Querying the Mitto Store API¶
This section relates to benefit #1 of using a Mitto store.
The store section contains the key which references a source field.
Mitto 3¶
In Mitto 3, you can view the results of the JSON store by running the job and then clicking STORE
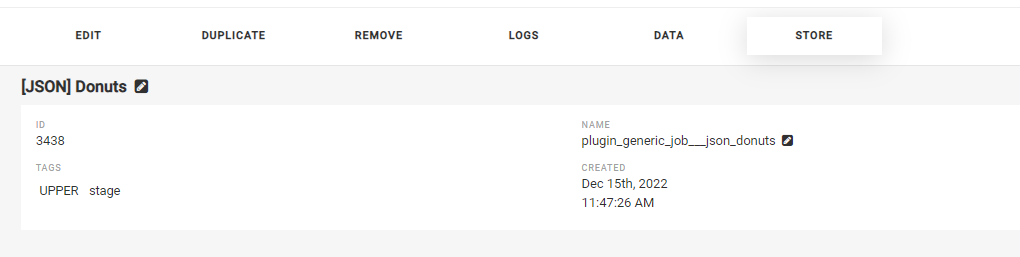
Under RECORD ID you can input one of the primary keys of a record from the
store to display additional information about the record. The key was
configured when the store was added to the job. In this case, the key is
id. Input the a primary key and click the search button to retrieve details
about the record from the store.

Mitto 2¶
You can use the name of the job and the key value in the resulting database table, to see the results of the JSON store in a browser.
Navigate to this URL in the browser:
https://{mitto_url}/api/v2/store/{job_name}/{key_value}
Note this URL has changed in Mitto v2.9 to /api/v2/store. In prior versions
of Mitto, the URL was /api/store.
Using our example job above:
https://stage.zuarbase.net/api/store/csv_store_example_csv/1

This is the record in the plugin_generic_jobs__json_donuts job’s store with the primary key 1.
Stores with multiple keys¶
Some Mitto stores can have multiple keys.
For example:
"store": {
"key": [
"date_start",
"ad_id",
"country"
]
}
In order to see the Mitto store the Mitto UI, you concatenate the key values with double underscore __.
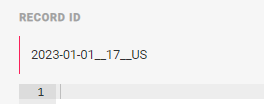
https://{mitto_url}/api/v2/store/{job_name}/{key_value_1}__{key_value_2}__{key_value_3}
Using the Mitto Store as a Source¶
This section relates to benefit #2 of using a Mitto store.
Read more about piping data from a Mitto store here.
Deleting a Mitto Store¶
If necessary, a job’s Mitto store can be deleted using a Mitto command line job.
When a job is configured to use a store, the store is located on the Mitto
server at this location: /var/mitto/store/{name of job}.
So using our CSV example from above, we can run a command to delete the store:
rm -rf /var/mitto/store/plugin_generic_jobs__json_donuts
Store job with no Output¶
You can create a job that outputs ONLY to a Mitto store and does not output data to a database (the default output).
Using the same example CSV file from above, here’s the modified job config:
{
input: {
use: flatfile.iov2#JsonInput
source: /opt/mitto_data/data/example_donuts.json
}
steps: [
{
use: mitto.iov2.steps#Input
}
]
store: {
key: [
$.id
]
}
}
Notice this job’s JSON config has no output or sdl objects. It also only has one step which relates to the input. The step itself has it’s standard transforms removed as well.
Why No Output?¶
This job configuration is useful for use cases where an API is the input and the output needs to be more than one database. With this job setup, the API is only queried once and the resulting data ends up ONLY in the Mitto store. As a follow up, you can create Mitto Store input jobs to pipe data from the Mitto store to other outputs.